
AI Blog Search - 基于 LangGraph 的自适应 RAG 系统(上)
🔧 项目简介
最近完成了一个基于 LangGraph 的自适应 RAG(检索增强生成)问答系统,支持网页内容索引和智能问答。这个系统不是一个简单的 RAG,而是使用 Agent 循环架构实现自适应检索,当检索效果不佳时会自动重写查询并重试。
本文将分为两部分介绍这个项目,本篇先介绍系统的核心特性和架构设计。
✨ 核心特性
| 特性 | 说明 |
|---|---|
| 🔄 自适应检索 | 检索失败时自动重写查询,最多 3 次迭代 |
| 🧠 LangGraph 工作流 | Agent 式架构:Retrieve → Grade → Rewrite/Generate |
| 📊 MMR 检索 | 最大边际相关性,平衡相关性与多样性 |
| 🔐 URL 去重 | 基于哈希的双重检查,防止重复存储 |
| ☁️ 云端向量库 | Qdrant Cloud 持久化存储 |
特性详解
🔄 自适应检索:普通 RAG 只检索一次,结果好坏全凭运气。而本系统在检索后会让 LLM 评估内容是否相关——如果不相关,会自动用同义词重写查询,再检索一次。这个”反思-重试”的循环最多执行 3 次,显著提升了回答质量。
🧠 LangGraph 工作流:LangGraph 是 LangChain 团队推出的状态图框架,比传统的链式调用更灵活。本系统用它实现了条件分支(相关→生成,不相关→重写)和循环(重写后回到 Agent),这在普通 Chain 里很难实现。
📊 MMR 检索:全称 Maximal Marginal Relevance。如果只按相关性排序,可能返回 10 个内容几乎重复的片段。MMR 在相关性和多样性之间做平衡,确保返回的片段既相关又互补。
🔐 URL 去重:一个工程细节但非常实用。用户可能多次输入同一个 URL,如果每次都重新索引,向量库会塞满重复数据。系统通过 MD5 哈希 + Qdrant 过滤实现了高效去重。
☁️ 云端向量库:使用 Qdrant Cloud 而非本地存储,数据持久化、应用重启后不丢失。对于个人项目来说,免费额度完全够用。
🏗️ 技术栈
LangChain + LangGraph # Agent 编排
Qdrant Cloud # 向量数据库
BGE-small-zh # 中文 Embedding
GPT-4o-mini # LLM
Streamlit # Web UI
为什么选择这些技术?
- LangGraph:相比传统的 LangChain 链式调用,LangGraph 提供了更灵活的状态图模型,非常适合实现 Agent 循环和条件分支
- BGE-small-zh:专门针对中文优化的 Embedding 模型,在中文语义理解上表现优异
- Qdrant Cloud:支持持久化存储,重启应用后数据不会丢失,且支持高效的向量检索
📐 系统架构
整个系统采用 Agent 式架构,而非传统的线性 RAG 流程。核心区别在于:传统 RAG 是一次检索、一次生成,而本系统在检索效果不佳时会自动”反思”并重试。
核心流程图
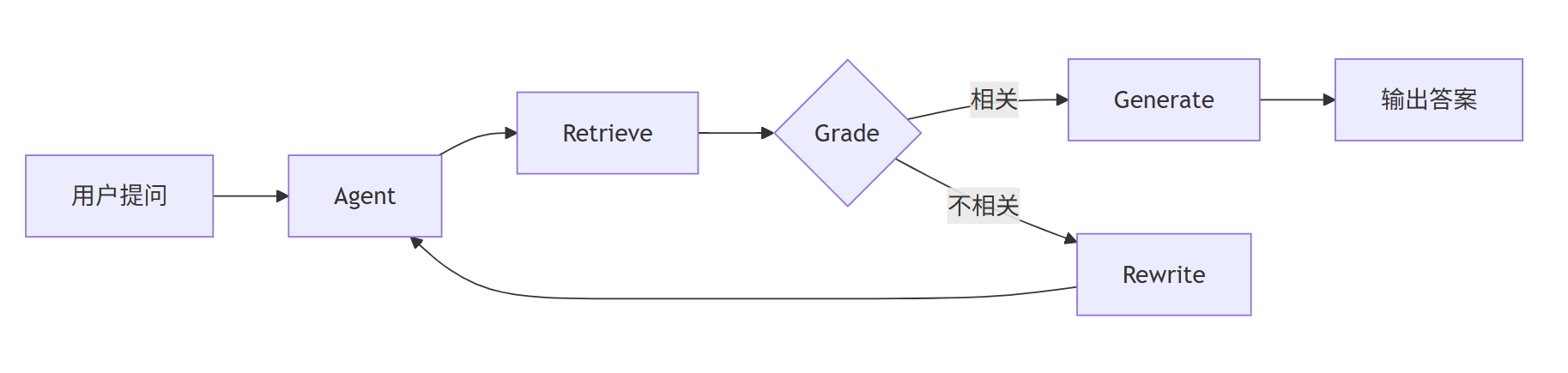
工作流程详解
1. 用户提问
用户输入问题后,系统将问题封装为 HumanMessage,初始化状态(包括 loop_step=0 记录重试次数),交给 Agent 处理。
2. Retrieve(检索) Agent 调用检索工具,从 Qdrant 向量数据库中查找语义最相关的文档片段。这里使用了 MMR(最大边际相关性) 算法,既保证相关性,又避免返回内容过于重复。
3. Grade(评估) 这是系统的”智能”核心。LLM 会评估检索到的片段是否真的能回答用户问题:
- 如果语义相关(即使用词不完全匹配),评为
yes - 只有完全无关时才评为
no
4. Generate(生成答案) 评估通过后,LLM 根据检索内容生成最终答案。Prompt 经过优化,要求直接回答问题,不说”根据文档…“之类的套话。
5. Rewrite(重写查询) 如果评估不通过,系统会智能重写查询语句。例如:
- 原问题:”同化的概念是什么?”
- 重写后:”同化 定义 含义 解释”
重写后的查询会重新进入 Agent 循环,最多重试 3 次,确保不会陷入无限循环。
为什么要自适应? 用户的提问方式往往和文档中的表述不一致。比如用户问”概念”,但文档里写的是”定义”。自适应重写通过同义词扩展,大幅提升了检索的召回率。
🚀 快速开始
1. 安装依赖
uv sync
2. 配置环境变量
创建 .env 文件:
QDRANT_HOST=your_qdrant_host
QDRANT_API_KEY=your_api_key
OPENAI_API_KEY=your_openai_key
3. 运行应用
uv run streamlit run main.py
📝 项目亮点
这个项目有几个值得关注的亮点:
- 不是简单 RAG - 使用 LangGraph 实现 Agent 循环,支持自适应重写
- 工程化思维 - URL 去重、索引优化、旧数据清理
- 生产级考虑 - 云端向量库、双重检查机制
- 中文优化 - 使用 BGE 中文模型,按语义切分
下篇预告:将深入代码实现,解析核心函数和优化细节。