
From Zero to Hero: A Deep Dive into Industrial RAG Architectures
在大模型(LLM)应用爆发的今天,RAG (Retrieval-Augmented Generation,检索增强生成) 已经从一个新颖的概念变成了企业级 AI 应用的标配。
但很多开发者在跑通了 Github 上的 Demo 后通常会发现:为什么 Demo 效果很好,上线后却一塌糊涂? 检索不准、回答幻觉、多轮对话逻辑混乱、成本居高不下…
本文剥离炒作,从工程架构设计的角度,深入探讨如何构建一个”生产可用”的 RAG 系统。我们将重点关注决策背后的“为什么”,而非仅仅堆砌代码。
Part 0: The “Why” behind RAG (基础认知)
什么是 RAG?
简单来说,RAG = Retriever (检索器) + Generator (生成器)。
LLM 就像一个”超级大脑”,但它的知识停留在训练结束的那一天(比如 2023 年)。RAG 就像是给了这个大脑一个”实时搜索引擎”或”企业知识库”。
核心流程:
[用户提问] -> [去知识库找资料] -> [把资料喂给 LLM] -> [LLM 结合资料回答]
为什么不直接微调 (Fine-tuning)?
这是最常见的误区。
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 纯 LLM | 简单、流畅 | 知识过时、严重幻觉、无法访问私有数据 | 通用闲聊、创意写作 |
| Fine-tuning | 深度定制语气/风格 | 成本高、更新知识极慢(需重新训练)、由于”灾难性遗忘”可能变笨 | 医疗/法律专用术语、角色扮演 |
| RAG | 数据实时、可解释性强(知道引用了哪篇文档)、成本低 | 架构复杂、依赖检索质量 | 企业知识库、客服、搜索助手 |
Part 1: The “Hello World” Trap (警惕 Demo 陷阱)
最基础的 Naive RAG 流程大家都很熟悉了:Indexing -> Retrieval -> Generation。 很多教程会给出这样的 LangChain 代码:
# ⚠️ 典型的 Demo 代码 - 生产不可用
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
qa_chain = RetrievalQA.from_chain_type(llm=ChatOpenAI(), retriever=vectorstore.as_retriever())
🚫 真实世界的失败案例:
案例:某金融客户问 “2024年Q3财报营收是多少?” 结果:系统检索出了一堆 2023 年 Q3 的数据,因为向量模型认为 “2023 Q3” 和 “2024 Q3”在语义上极度相似。 教训:单纯的向量检索无法处理”精确匹配”(数字、年份、产品型号)。
生产环境的三大挑战:
- 切分太死板:500 字符可能刚好把”问题”和”结论”切到了两个不同的块里。
- 检索单一:Dense Vector 对模糊语义强,对专有名词弱。
- 无视用户意图:用户说”再具体点”,Naive RAG 根本不知道这个”再”是指什么。
Part 2: Data Engineering Strategies (数据决策指南)
“Garbage In, Garbage Out”. RAG 的上限由数据决定。
1. Chunking 策略选择
不要无脑用 RecursiveCharacterTextSplitter。
| 场景 | 推荐策略 | 核心理由 |
|---|---|---|
| 结构化文档 (法规/合同) | 按章节/Markdown标题切分 | 每一条法规必须完整,不能从中间截断。 |
| 对话记录 (会议/客服) | 按对话轮次切分 | “A说…” 和 “B回复…” 必须在一起才能保留上下文。 |
| 技术文档 (API/代码) | Semantic Chunking (语义切分) | 代码块和它的解释文本必须在同一个 Chunk 里。 |
| 通用内容 (新闻/博客) | Recursive + 15% Overlap | 简单有效,Overlap 是为了防止代词(He/It)丢失指代对象。 |
2. Parent Document Retriever (小索引,大内容)
这是一个解决”检索粒度 vs 生成粒度”矛盾的架构设计。
- 核心洞察:类似于电商搜索。搜索时你匹配的是精简的”商品标题”(精准),但查看时你看到的是完整的”商品详情页”(丰富)。
- 实现原理:
- 将文档切成 Child Chunks (比如 100字) 做向量索引 —— 易于精准命中。
- 命中 Child 后,系统通过 ID 找到并返回对应的 Parent Chunk (比如 500字) 给 LLM。
3. Embedding Model Selection (模型选型指南)
别只盯着 OpenAI,不同的业务场景需要不同的模型。
| 模型类别 | 代表模型 | 核心优势 | 适用场景 | 劣势 |
|---|---|---|---|---|
| 通用闭源 | text-embedding-3-small (OpenAI) |
运维极简,多语言支持好,维度可变 | 快速验证 MVP,无需自建 Infra | 数据需出境,成本随量增 |
| 中文最强 | bge-m3 (BAAI) |
多功能 (Dense + Sparse + Multi-Vector),长文本支持 (8192) | 中文生产环境首选,需精细化检索 | 推理资源消耗较大 |
| 晚期交互 | ColBERT | Token 级交互,精确捕捉细微语义差异 (精确到 Excat Match) | 对查准率要求极高的场景 | 存储膨胀 10-20 倍,查询慢 |
4. Vector Database Selection (向量库选型)
选择向量库主要看你的数据规模和现有技术栈。
| 类别 | 工具 | 推荐理由 | 适用场景 |
|---|---|---|---|
| 原生向量库 | Qdrant, Milvus, Weaviate | 性能怪兽。Qdrant (Rust) 极快且资源占用低;Milvus 分布式强。 | 亿级数据量,高并发,需要高级 Filter |
| 嵌入式/轻量 | LanceDB, Chroma | 无需运维。基于文件的 Serverless 架构,甚至可以直接在该 S3 上查询。 | 本地运行、CI/CD、单机应用 |
| 传统库扩展 | pgvector (Postgres), Elasticsearch | 栈一致性。如果已有 PGsql,直接开插件是运维成本最低的方案。 | 不想引入新组件,数据量在千万级以下 |
Part 3: Advanced Retrieval (检索黑魔法)
1. Query Rewriting & Expansion (查询改写与扩展)
用户的 Query 通常是模糊的。
- Multi-Query (多路查询):
- 原理:让 LLM 基于原始问题生成 3-5 个不同角度的相似问题,并行检索,取最后结果的并集。
- 解决痛点:用户因措辞不当导致的”漏召回”。
- HyDE (假设性文档嵌入):
- 原理:让 LLM 先生成一个”假设性答案”,再用这个答案去检索。
- 解决痛点:Query 很短或很抽象,与文档在向量空间中语义距离太远。
- Query Decomposition (多步拆解):
- 原理:将复杂问题拆解为多个简单的子问题。
- 场景:用户问”对比2023和2024年的营收变化”。
- 流程:
1. 2023营收是多少?->2. 2024营收是多少?->3. 对比两者。单步检索永远比混合检索准。
HyDE 工作原理流程:

核心逻辑:在向量空间中,”答案”和”标准答案”的相似度,远高于”问题”和”标准答案”的相似度。
2. Hybrid Search (混合检索)
解决”专有名词搜不到”的问题。
- Vector Search (稠密向量): 擅长语义理解。搜 “苹果手机” 能匹配 “iPhone”。
- Keyword Search (BM25/稀疏向量): 擅长精确匹配。搜 “RTX4090-Ti” 绝不会匹配 “RTX4090”。
- RRF (Reciprocal Rank Fusion): 融合算法。公式
Score = 1 / (k + Rank)。- 为什么有效:它不依赖分数(Dense Score 是 0.8,BM25 是 15.2,无法直接相加),只看排名。
- 参数 K:通常设为 60。这个常数主要用于平滑排名靠前的文档权重,防止排名第一的文档统治整个结果列表。
3. Re-ranking (重排序)
类比:
- 检索 (Retrieval) 是”海选”:从 100万个文档里快速捞出 Top 50,速度快,但不够准。
- 重排序 (Re-ranking) 是”面试”:用更精细的模型(Cross-Encoder)把这 50 个文档逐字细读,重新打分,选出 Top 5。
✅ 经验值:加上 Re-ranking 通常能带来 10%-20% 的准确率提升。
- 推荐模型:
bge-reranker-v2-m3(多语言/中文强),Cohere Rerank(闭源最强)。- ⚠️ 注意:Cross-Encoder 计算昂贵 (O(n×m)),建议 Top-K ≤ 50,否则延迟会显著增加。
Part 4: From Chain to Graph (Agentic RAG)
传统的 LangChain 是流水线工 (A -> B -> C),不管中间哪一步错了,只能硬着头皮往下走。 LangGraph 是智能管理者,基于状态机 (State Machine),可以循环、重试、纠错。
核心架构:Self-Correcting RAG
我们不看代码,看逻辑流转:
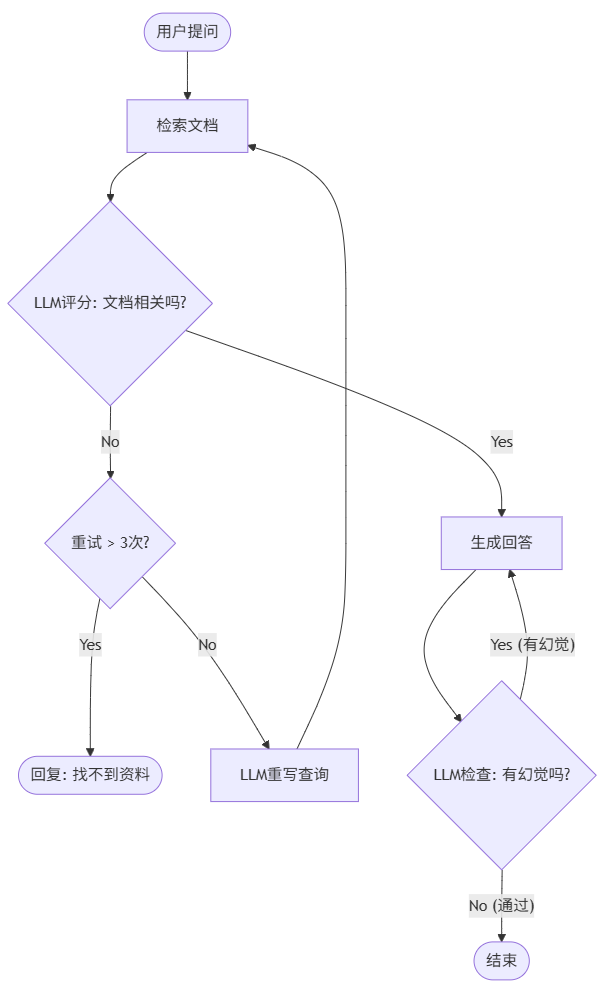
设计思想:
- 闭环 (Loop): 检索不到不立刻放弃,而是尝试换个说法(Rewrite)再搜一次。
- 自我反思 (Reflection): 每一步都有一个裁判(Grader)在检查质量。
- 防死循环 (Safety Guardrails): 必须设置
max_retries(如 3 次)。如果反复重写 Query 还是搜不到,说明知识库里真没有,此时应优雅降级(Fallback),而不是让 Agent 陷入无限循环消耗 Token。
Part 5: Production Pitfalls (踩坑实录)
1. 安全:Metadata Filtering (血泪教训)
🚑 真实事故:某 HR 系统。用户问”查一下张三的工资”。Naive RAG 检索出了所有包含”张三”和”工资”的文档。虽然 UI 上没显示,但 API 返回的 Context 里包含了 CEO 的工资单。
正确做法:Pre-filtering (预过滤)。 在检索发生之前,这就应该被拦截。
search(query, filter={"department": "user_dept"})。千万不要先把数据捞出来再在内存里过滤!
2. 成本:Semantic Cache
LLM 的 Token 很贵,向量数据库的查询也耗 CPU。
- 问题:用户问 “How to reset password” 和 “Reset pwd guide” 其实是一回事。
- 解法:语义缓存。 如果当前问题的向量与历史问题的向量相似度 > 0.95,直接返回缓存的历史答案。既从 3秒 变成 0.1秒,又省了钱。
Part 5.5: Observability (可观测性 - 拒绝黑盒)
RAG 系统比普通应用更难调试,因为中间全是”概率”。
- Tracing (链路追踪): 必须能看到
Query -> Rewrite -> Retrieval (Top K docs) -> Generation的全过程。 - 工具推荐:
- LangSmith: LangChain 官方,集成度最好,可视化强。
- Langfuse: 开源优选,该有的都有,支持 Self-host。
- 关注指标:
- Latency P99: 99% 的请求耗时是多少?(RAG 很容易慢)
- Token Usage: 这一次问答烧了多少钱?
- Step Latency: 到底是检索慢,还是 LLM 生成慢?
Part 6: Evaluation (如何评估)
没有评估的 RAG 就是在”盲改”。
DeepDive 指标解读指南:
| 指标 | 出现低分意味着什么? | 如何改进? |
|---|---|---|
| Context Precision (查准率) | 检索器太烂,混入了大量无关噪音。 | 优化 Chunking,上 Re-ranking。 |
| Context Recall (查全率) | 漏掉了关键信息。 | 增大 Top-K,尝试 Hybrid Search。 |
| Faithfulness (忠实度) | LLM 在胡编乱造,没利用 Context。 | 调整 Prompt,强调”仅根据上下文回答”。 |
| Answer Relevance | 答非所问。 | 可能是 Query 理解错了,尝试 Query Rewriting。 |
Ground Truth (黄金数据集) 哪里来?
RAGAS 的局限性在于它是用 “LLM 评价 LLM”。更严谨的评估需要人工标注的 Golden Dataset。
- 生成方法:让业务专家提供 50 个高频问题,并手动从文档中找出”标准答案”片段。
- 评估流:跑一遍 RAG,拿生成的 Answer 和人工的标准答案算语义相似度。
Bonus: The Frontier (2025 前沿方向)
- Graph RAG (知识图谱):
- 痛点: 现在的 RAG 都是”碎片化”的。问”A和B有什么关系?”,单纯搜A和单纯搜B都很难把关系连起来。
- 解法: 用 LLM 提取实体关系 (Entity-Relation),构建图谱。检索时在图上游走。
- Multi-modal RAG (多模态):
- 痛点: 很多知识在图片、PDF 表格、PPT 图表里。
- 解法: 使用 ColPali 等多模态检索模型,直接对图片进行 Embedding 和检索,不再依赖 OCR 转文字。
Conclusion: 实施路线图
从 0 到 1 建设工业级 RAG,建议分五步走:
- MVP 阶段: Naive RAG。跑通流程,验证数据价值。
- 优化阶段: 引入 Hybrid Search + Re-ranking。解决”搜不准”的核心痛点。
- 可观测阶段: 接入 Langfuse/LangSmith。没有 Tracing 就不允许上线。
- 成熟阶段: 引入 LangGraph + Evaluation。建立自动化评估体系,引入 Agent 自我纠错(带 Retry Limit)。
- 生产阶段: 完善 Security (ACL) + Caching。关注性能、成本与合规。
Glossary (术语表)
| 缩写 | 全称 | 解释 |
|---|---|---|
| RAG | Retrieval-Augmented Generation | 检索增强生成。通过外挂知识库让 LLM 获得实时信息。 |
| HyDE | Hypothetical Document Embeddings | 假设性文档嵌入。先生成假答案,再用假答案去检索真文档。 |
| RRF | Reciprocal Rank Fusion | 倒数排名融合。一种将多个检索结果列表(如 Keyword + Vector)合并排序的算法。 |
| ColBERT | Contextualized Late Interaction over BERT | 基于 BERT 的晚期交互模型。通过保留 Token 级别向量来实现超高精度的检索。 |
| Query Decomposition | Query Decomposition | 查询拆解。将复杂查询分解为多个简单子查询的策略。 |
| Ground Truth | Ground Truth | 地面实况/标准答案。人工标注的高质量问答对,用于评估 RAG 的准确性。 |
| ACL | Access Control List | 访问控制列表。用于控制用户对数据的访问权限。 |
| PII | Personally Identifiable Information | 个人敏感信息(如身份证、手机号),需在 RAG 流程中脱敏。 |
References (参考资料)
- LangChain Documentation
- LangGraph Documentation
- Ragas Evaluation Framework
- ColBERT Paper
- HyDE Paper
- Microsoft GraphRAG
- ColPali: Efficient Document Retrieval with Vision Language Models
希望这篇文章能帮助你在构建 RAG 系统的道路上少走弯路!Happy Coding! 🚀